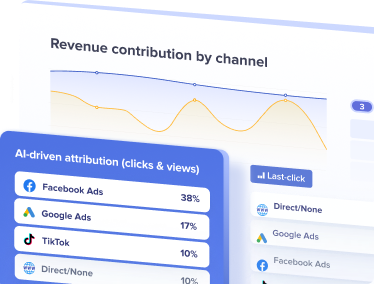
Solving (direct)/(none) with Machine Learning
Even so the problem described in this article still remains the same, our approach has moved forward.
We still use machine learning to help future-thinking marketers to measure true value of their marketing channels, but in a much improved way.
Read about it in our announcement here.
This article was originally published on the CXL.com blog by Constantine Yurevich, CEO of SegmentStream.
Urchin, later acquired by Google, invented an amazing way of measuring campaign performance by using last non-direct click attribution and first-party cookies. The solution was perfect—for earlier times:
- People used mostly one device.
- Smartphones were rare.
- Advertisers avoided mobile apps and browsers because user experience was, at that time, horrible.
In most cases, the assumption that users converted on the same browser and the same device as their first site visit was fair.
The contemporary customer journey is more complex: retargeting, cross-domain tracking, triggered emails, targeted promotions. Single-channel attribution models don’t reflect reality, but marketers continue to make decisions based on these outdated models.
Patch-work solutions for multi-channel attribution struggle to accommodate cross-device and cross-browser usage, and private browsing. But machine learning has a potential solution that turns traditional, retrospective attribution on its head.
Cross-device, cross-browser, and private browsing tracking is hard impossible.
Session-stitching can improve complex tracking, but it’s an imperfect system—and the task isn’t getting easier.
After the iPhone launched in 2007 to mass adoption, analytics were never the same. If a decent percentage of users weren’t authenticated (i.e. logged in) on your website, stitching a user’s website sessions was nearly impossible.
When users started a journey on a mobile device but eventually purchased on a desktop, the mobile visit was undervalued and the desktop visit overvalued.
Of course, you don’t need to change devices to tank tracking.
Cross browser
Most popular mobile apps (e.g., Twitter, Facebook, LinkedIn, Instagram, YouTube, etc.) use their own browser. Whenever you click on the app, an in-app browser opens with a unique cookie.
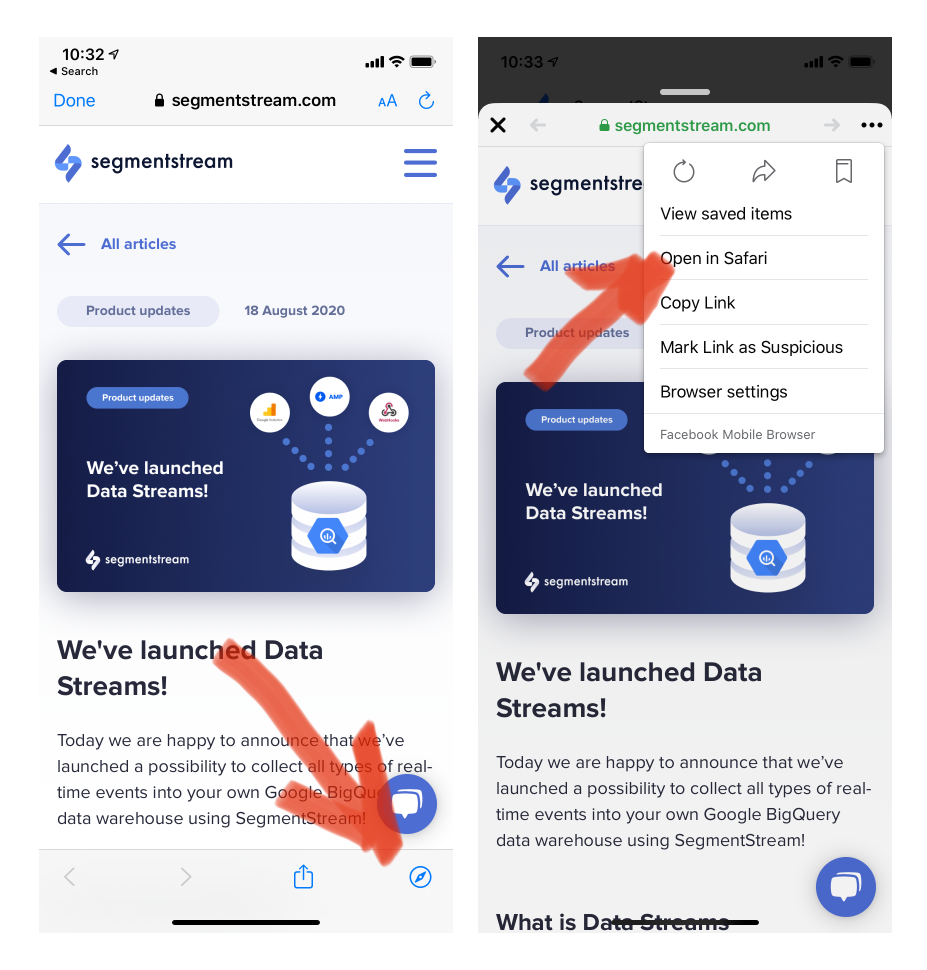
In most cases, people don’t stay within the in-app browser, eventually going to their browser of choice (in the example above, Safari). Even on one device, a cross-browser experience completely ruins web and marketing analytics as we know it now.
The result is a lot of direct traffic without any insight into what’s driving it up. Meanwhile, other channels appear (wrongly) to be underperforming.
The same happens when you use Google’s AMP viewer instead of a signed exchange. (Most marketers don’t even know about the signed exchange. You can remove yourself from that category by reading the documentation here.)
As a B2B business, we’ve struggled with this problem for a long time. Mobile traffic looks less conversion-ready (and less valuable) than desktop traffic. But plenty of research shows that most customer journeys start on mobile.
Even if mobile traffic is a huge driver of new users and potential customers, it’s hard to justify pushing resources there when we don’t have the data to back it up.
Oh, and don’t forget about private browsing.
Private browsing
After the GDPR policy announcement in 2016, users became increasingly sensitive about how they’re tracked. The interest in private browsing, VPNs, and secure browsers like Tor or Brave went from geeky to standard.
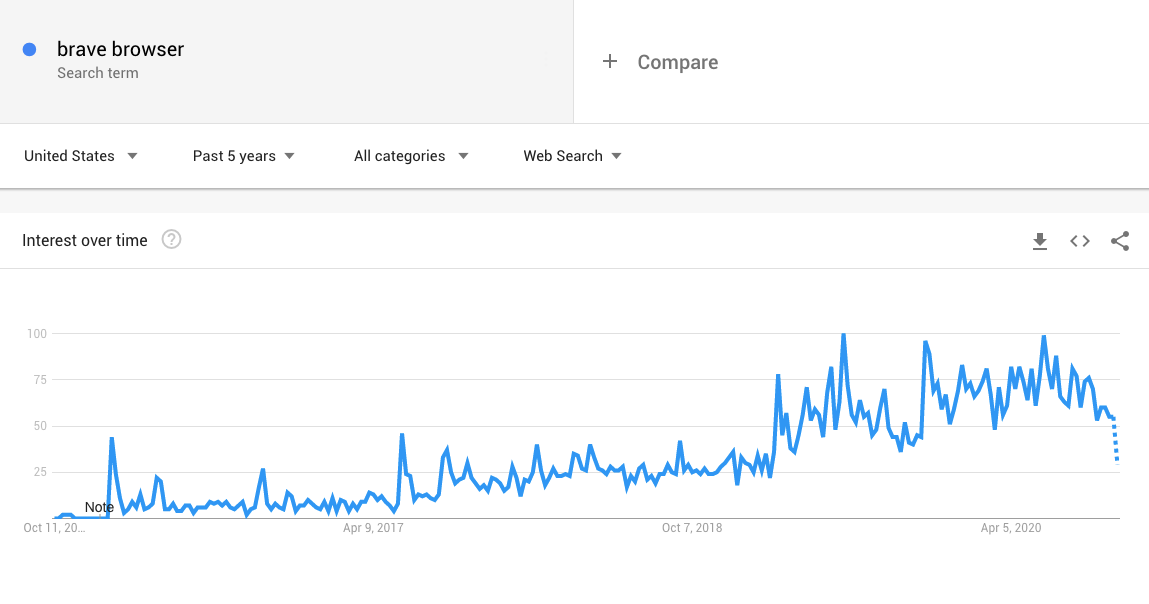
From the other side, technology companies like Apple have limited tracking. A good example is the launch of ITP 2.1 in February 2019, which made it harder to track even unaware users, both cross-domain and cross-session.
These three factors have made multi-channel attribution, which was already an elusive, Holy Grail, even harder.
How machine learning changed everything
The problems outlined above make it clear that deterministic attribution alone won’t work. Attribution needs to be strengthened by a probabilistic (i.e. predictive) approach.
The challenge of deterministic attribution is precise stitching of a conversion with an initial traffic source. If a user isn’t authenticated and a conversion happens on another device or browser, the whole concept is ruined.
But what if you could use modelled (predicted) conversions instead of actual conversions? What if you could use the value of the session—instead of the value of the conversion—to evaluate channels?
Even for a website with fewer than 100,000 unique users per month, our experience—with dozens of clients and our own site—shows that it’s possible to build highly accurate models that predict conversions with up to 95% accuracy. This is a whole new era of attribution: Attribution that looks into the future instead of looking into the past.
Below, I describe how to apply our AI-driven approach to fight the “(direct)/(none)” problem when analysing the efficiency of marketing channels and campaigns.
Developing a Machine learning model
This is the part of what our product, SegmentStream, does. But, as I outlined previously, you can build your own model in Google BigQuery.
The broad strokes of the process look like this:
- Mine features: Gather data on the recency, frequency, and monetary value of micro-conversions. Fold in contextual data, like user device, region, screen resolution, etc.
- Train your model: I share sample SQL code in my prior article that covers, for example, how to train a model on users’ probability to buy in the next seven days. It takes about a minute, and you can retrain your model daily.
- Evaluate your model: Visualize characteristics like precision-recall curve, precision and recall versus threshold, and the ROC curve.
- Build your attribution model: Allocate value to each source, then calculate a delta between the two sessions.
Once you have a working model, you can decide how much influence you want machine learning to have on your attribution.
Choosing between hybrid or full-on machine-learning models
For simplicity, let’s compare retrospective (i.e. deterministic) and predictive attribution scenarios for the following case:
- A user clicks on a Google search ad and opens a mobile version of a fashion ecommerce website.
- The user browses a few product pages, checks sizes in stock, views some images, and adds some links to their iPhone Notes.
- At home, the user opens the site on desktop by clicking the links from Notes, which sync with their Macbook.
- Eventually, the user makes a purchase with a total value of $500.
We’ll carry that example through three scenarios: deterministic attribution, a hybrid approach, and a fully predictive version
Last non-direct click vs. retrospective multi-touch
Whether you use single-channel, last non-direct click, or retrospective multi-touch attribution, the result is the same. The initial channel will get zero value; the entire conversion is attributed to the last touchpoint (i.e. direct):
| Name | sessions | conversions | revenue |
|---|---|---|---|
| google / cpc | 1 | 0 | $0.00 |
| (direct) / (none) | 1 | 1 | $500.00 |
Results
This happens because your analytics can’t stitch together the initial visit from a search ad and a later direct visit (on another device, browser, etc.).
Hybrid predictive approach
Adding a predictive approach to the traditional model improves attribution. Imagine you used thousands of user sessions to train your model to predict the probability to buy in the next 7 days based on user behavior and contextual features.
An accurately trained model on thousands of customer journeys can predict the probability to buy in the next 7 days (as well as revenue) effectively.
The model is accurate because it’s trained on full journeys, which then define values for “interrupted” or “continued” journeys:
- Full journeys. Valuable sessions that end with a conversion.
- Interrupted journeys. Valuable sessions that didn’t end with a conversion because of private browsing or cross-platform behavior.
- Continued journeys. Outstanding “(direct)/(none)” sessions that end rapidly in conversion because a user already interacted with the website from another device or in private mode.
This way, during the first session initiated by the Google ad click, the model predicts some non-zero value of possible future revenue — even if the user doesn’t convert right away. Say that the model predicts that a user has a 37.5% probability to convert, and predicted revenue from this session is $300.
During the next session, the user comes back to the website directly and makes a purchase. Instead of predicted conversions and revenue, we see an actual conversion and revenue of $500.
The overall value of the two sessions (predicted + actual) is equal to $800, which is, of course, more than the actual money the ecommerce company received in their bank account. The final step, then, is normalization:
- Attributed value for google/cpc = $300/($300+$500) = $300/$800 = 0.375 x $500 = $187.5
- Attributed value for (direct)/(none) = $500/($300+$500) = $500/$800 = 0.625 x $500 = $312.5
| Name | sessions | predicted conversions | actual conversions | predicted revenue | actual revenue | attributed revenue |
|---|---|---|---|---|---|---|
| google / cpc | 1 | 0.375 | 0 | $300.00 | $0.00 | $187.50 |
| (direct) / (none) | 1 | 1 | $500.00 | $312.50 |
At first glance, this looks like a much more credible distribution of value—if, of course, you’ve got an accurate model.
(You can test this via “model evaluation,” which uses ROC/AUC metrics. You train your model on some data, and then feed absolutely new data to the model and see how many false positives or true negatives you’ve got. If you do it in BigQuery, you already have built-in functions.)
Expect your model to evolve:
- Once you have full-month data, you can add a day-of-the-month correlation, which might be relevant for ecommerce because people receive—and spend—their salaries on specific days.
- Once you have a whole year of data, you can also adapt to seasonality, sale periods, and other contextual events (e.g., COVID-19, iPhone launch, massive TV buying, etc.).
The goal of predictive attribution is to improve the overall CPA/ROAS of the whole marketing mix, not a specific channel or campaign.
Fully predictive approach
Personally, I consider this approach the most progressive and accurate. It can dramatically improve your marketing mix modeling decisions and significantly increase your ROAS.
It can also cause the most angst. People get psychologically attached to the things they’re used to, even if a machine-learning model with only 76% accuracy might be more accurate than last non-direct attribution.
This approach is also, not surprisingly, the most mind-blowing for CFOs. You don’t look at actual conversions at all (save for when you’re training your model), operating only with predicted conversions and revenue, looking into the future.
In other words, you take into account the “value” of the session, not the conversion. Your CFO can still analyze retrospective data, but this has nothing to do with decisions about your marketing mix.
As in the previous approach, you train the model to predict the probability to buy in the next 7 days based on user behavior and contextual features. But, unlike the previous approach, your attribution report contains only predicted values.
Imagine that, for the first session, the model predicted the probability to buy of 37.5%, with a revenue of $300. For the second session—despite the conversion that actually happened—the model predicted a probability to buy of 25%, with $125 in revenue.
You can see that google/cpc has a much bigger contribution compared to (direct)/(none). To avoid confusing your CFO, you still can normalise values to sum up to actual revenue:
Session 1 normalised value = ($500 / ($300 + $125)) * $300 = $352.94
Session 2 normalised value = ($500 / ($300 + $125)) * $125 = $147.06
| Name | sessions | predicted conversions | actual conversions | predicted revenue | actual revenue | attributed revenue |
|---|---|---|---|---|---|---|
| google / cpc | 1 | 0.375 | 0 | $300.00 | $0.00 | $352.94 |
| (direct) / (none) | 1 | 0.25 | 1 | $125.00 | $500.00 | $147.06 |
This way, you can analyze channels and campaigns with the power of machine learning despite being unable to deterministically stitch users between different devices. We’re already doing this for our clients and, after 2–3 months of testing, have achieved 260% ROAS increase from Facebook Ads.
But what happens as full journey data continues to dry up?
Predictive attribution without full journeys
If deterministic stitching is hard and—based on more devices, more browsers, and more privacy restrictions—only getting harder, will that undermine the quality of future models?
As long as some portion of people still purchase during a single journey (i.e. “full journeys”), you’ll have required data to learn. But with only interrupted journeys, it could still work. Imagine that with only interrupted journeys, 100% of conversions (based on last interaction) are (direct)/(none).
You can still recognize patterns of users who engage and tend to buy. A subset of direct users will share features (i.e. events) with users who come from Facebook. The model doesn’t know where people came from; you show only behavior for on-site and contextual events.
So the model sees that a user from a Facebook in-app browser behaves like users who tend to buy (trained on direct traffic). And it will allocate non-zero values to such sessions.
Conclusion
Whether you use a predictive approach as your primary attribution method or as a validating approach is up to you. In either case, you’ll be able to demonstrate the value of some campaigns that are otherwise impossible to know.
Start by building your model, which you can do in Google BigQuery or with a solution like our own. Then, try deploying a hybrid or fully predictive attribution model to see whether it increases your ROAS and better balances your marketing mix.
You might also be interested in



Optimal marketing
Achieve the most optimal marketing mix with SegmentStream
Talk to expert